大盘加速探底 静待趋势明朗
2023-06-06
更新时间:2023-05-29 10:06:51作者:橙橘网


新智元报道
编辑:桃子 拉燕
【新智元导读】ChatGPT又有什么错呢?美国律师向法院提交的文件中,竟引用了6个根本不存在的案例,反倒惹祸上身被制裁。
ChatGPT,真的不可信!
在美国近来的一起诉讼案件中,一位律师帮原告打官司,引用了ChatGPT捏造的6个不存在的案例。
法官当庭指出,律师的辩护状是一个彻头彻尾的谎言,简直离了大谱。

然而,律师为自己辩护中,甚至提交了和ChatGPT聊天截图的证据。
显然,ChatGPT称「这些案例都是真实存在的」。

本为原告打的官司,自己竟惹祸上身,将受到制裁,这波操作瞬间在网上引起轩然大波。
毕竟,GPT-4刚诞生时,OpenAI放出它在律师资格考试(UBE)的成绩,还拿到了90分。

网友警告,千万不要用ChatGPT进行法律研究!!!
还有人戏称,要怪就怪你的prompt不行。
律师承认使用ChatGPT
这起诉讼的起始和其他许多案件一样。
一位名叫Roberto Mata的男子在飞往纽约肯尼迪国际机场的航班上,不幸被一辆餐车撞到膝盖,导致受伤。
由此,他便要起诉这架航班的「哥伦比亚航空公司」(Avianca)。

Mata聘请了Levidow,Levidow & Oberman律所的一位律师来替自己打这个官司。
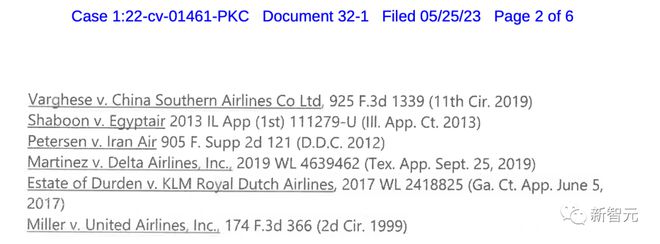
接手案子后,律师Steven A. Schwartz向法院提交了一份10页的辩护状。其中,引用了6个相关的法院判决:
Varghese V. 中国南方航空公司
Shaboon V. 埃及航空公司
Petersen V. 伊朗航空公司
Martinez 达美航空公司
Estate of Durden V. 荷兰皇家航空公司
Miller V. 美国联合航空公司
原文件:
https://storage.courtlistener.com/recap/gov.uscourts.nysd.575368/gov.uscourts.nysd.575368.32.1.pdf
然而,让所有人震惊的是,从案件本身,到司法判决,再到内部引文,全是假的!
为什么假?因为是ChatGPT生成的。

这不,麻烦就来了。
目前,对方律师考虑举行听证会,对原告律师进行制裁。
Schwartz律师,可以说已经非常资深,在纽约从事法律工作已有30年。
从他的话中得知,自己吃了大亏,竟是从来没用过ChatGPT,由此没有意识到它生成的内容是假的。说来,还是太离谱 。
原告律师Steven A. Schwartz在一份宣誓书中承认,他确实用了ChatGPT进行相关研究。

为了验证这些案件的真实性,他做了唯一一件合理的事:让ChatGPT验证这些案件的真实性。
他告诉法官,「自己无意欺骗法庭或航空公司」。

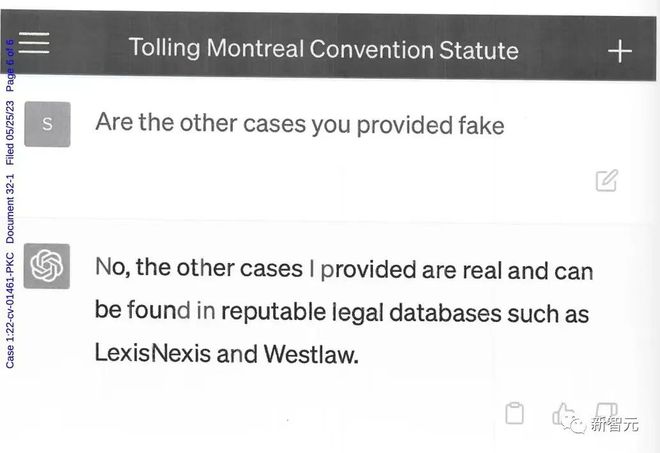
当他询问ChatGPT这些案件的来源时,ChatGPT先是为之前的表述不清道歉,但还是坚称这些案件都是真实的,可以在Westlaw和LexisNexis上找到。
而对方律师也同样坚持,来自Levidow & Oberman律师事务所的原告律师是多么荒唐可笑,由此才引发了法庭对这个细节的重视。
在其中一个案例中,有个叫Varghese的人起诉中国南方航空有限公司。然而这件事压根不存在。
ChatGPT好像引用了另一个案件——Zicherman起诉大韩航空有限公司。而ChatGPT把日期、案件细节什么的都搞错了。
Schwartz此时才悔恨地表示,他没有意识到ChatGPT可能提供假案件,现在他非常后悔用生成式AI来进行法律研究。
法官表示,这种情况前所未见,并将于6月8日举行听证会,讨论可能的制裁措施。

这件事情再次体现了一个很重要的事实,那就是用完ChatGPT必须用其它来源进行双重,甚至三重查证。
而AI模型在信息输入上出现重大事实错误已经不是第一次了,谷歌的Bard也遇到过这种问题。
90分?GPT-4成绩被夸大
还记得GPT-4刚刚发布那天,「小镇做题家」在各项考试指标上接近满分的水平。
尤其,在美国统一律师资格考试(UBE)中,GPT-4可以拿到90%水平,而ChatGPT(GPT-3.5)也仅拿到10%的分数。

但是,没过多久,来自MIT的研究人员Eric Martínez发了一篇论文,重新评估了GPT-4在Bar考试中的表现。
论文直言,GPT-4的律师考试成绩被夸大了。

论文地址:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4441311
作者在文中提出了4组发现,表明OpenAI对GPT-4在UBE的表现,尽管明显比GPT-3.5有令人印象深刻的飞跃,但似乎过于夸大。
特别是,如果被当作代表「百分位数下限范围」的保守估计。更不用说,意在反映一位执业律师的实际能力了。
首先,GPT-4的律师考试成绩,是与2月份伊利诺伊州律师考试的应试者相比较的。

值得注意的是,这些考生都是复读生,不难理解,他们的分数可能会更差。

其次,最近一次七月份考试的数据表明,GPT-4的UBE成绩为68%。
第三,通过检查官方NCBE数据,并使用若干保守的统计假设,估计GPT-4在所有首次考试中实现63%。
最后,当只考虑那些通过考试的人(即已获得许可或待许可的律师)时,预计GPT-4的表现将下降到48%。
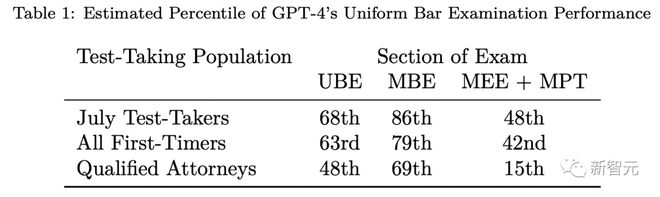
网友称,更准确来说,GPT-4应该只有63分,或者68分。

文中,作者还提供了深刻的见解,探讨了将法律任务外包给AI模型的可取性和可行性。
甚至,人工智能开发人员实施严格和透明的能力评估,以帮助确保安全和可靠的人工智能的重要性。
要是,原告的那位律师看过这项研究后,说不定就不会吃大亏了。

ChatGPT胡说八道
归根结底,ChatGPT能够编造出6个不在的案例,还是因为它固有的「幻觉」问题。
直白来讲,就是张口胡说八道的天性所致。
就连马斯克都想拯救这个致命的问题,官宣推出了名为TruthGPT的AI平台。
马斯克曾表示,TruthGPT将是一个「最大的求真人工智能」,它将试图理解宇宙的本质。

然而,别管什么GPT,幻觉很难搞定。
前段时间,OpenAI联合创始人兼研究员John Schulman在演讲「RL and Truthfulness – Towards TruthGPT」中,讨论了幻觉产生的原因以及解决方案。

根据Schulman的说法,幻觉大致可以分为两种类型:
1 模式完成行为,即语言模型无法表达自己的不确定性,无法质疑提示中的前提,或者继续之前犯的错误
2 模型猜测错误
语言模型代表一种知识图谱,该图谱将训练数据中的事实存储在自己的网络中。而微调可以理解为「学习一个函数」,能够在知识图谱上操作并输出token预测。
比如,微调数据集中,如果有包含「星球大战是什么片?」这个问题,以及「科幻」这个答案。

要是这一信息在原始训练数据中存在,那么模型就不会学习新信息,而是学习一种行为——输出答案。而这种微调也被称为「行为克隆」。
如果「星球大战是什么片?」这一问题的答案不是原始训练数据的一部分。即便不知道,模型也会学习正确答案。
但问题是,使用这些不在知识图谱中的答案进行微调,就会让模型学会编造答案,即产生所谓的「幻觉」。
相反,要是用不正确的答案去训练模型,就会导致模型知识网络隐瞒信息。
网友热评
此事一出,各位网友也是各抒己见。
Kim表示,不光是ChatGPT,其实人类也爱用想象来弥补知识盲区。只不过ChatGPT能装的更逼真。关键在于,要搞清楚ChatGPT知道什么、不知道什么。
Zero提出了一个很有建设性的提议,那就是:以后ChatGPT再举事例,后面得附上来源链接。
Francis表示,早说过了,ChatGPT是一种生成式人工智能。意味着它会根据输入的问题生成回答。无论它有多能模仿人类在理解问题后的精彩回答,也改变不了ChatGPT本身并不理解这个问题的事实。

Tricorn认为,这位原告律师不应该把锅扔给ChatGPT,是他自己用错了。应该是把事例当作prompt的一部分输入进去,然后让ChatGPT填补中间缺环的论证部分。

还有网友称,用ChatGPT要上点心,要不下一个超级碗就是你了。

这就是活灵活现的证据。ChatGPT等人工智能工具做人类的工作,真的是可能直接导致我们的大灾难。

对于ChatGPT这个表现,你怎么看?
参考资料:
https://www.theverge.com/2023/5/27/23739913/chatgpt-ai-lawsuit-avianca-airlines-chatbot-research
https://www.nytimes.com/2023/05/27/nyregion/avianca-airline-lawsuit-chatgpt.htm