字节爆出AI“套壳”瓜,低调是原罪?
2023-12-18
更新时间:2023-12-18 10:34:04作者:橙橘网


出品|虎嗅科技组
作者|齐健
编辑|王一鹏
头图|视觉中国
在大模型热潮中,一直保持低调的字节跳动,日前也被曝出了“套壳“的瓜。
当地时间12月15日,外媒The Verge曝出字节跳动正在秘密研发一个被称为“种子计划”(Project Seed)的AI大模型项目。据称该项目在训练和评估模型等多个研发阶段调用了OpenAI的应用程序接口(API),并使用ChatGPT输出的数据进行模型训练。
在API调用和对输出内容的使用方面,OpenAI的使用协议明确规定了:禁止使用输出开发竞争模型。
在2023年11月14日更新的使用条款中还规定了:
OpenAI的使用条款中对于违规用户的处理办法是:在提前通知的情况下,随时终止服务。

OpenAI服务条款中禁止的事项
而目前,隶属于字节跳动公司名下的部分GPT使用权限均已被OpenAI封禁。
OpenAI发言人Niko Felix在一份声明中表示:“所有API客户必须遵守我们的使用政策,以确保我们的技术用于正确用途。虽然字节跳动对OpenAI的API使用量很少,但在进一步调查期间,我们已暂停了他们的帐户,如果我们发现他们的使用不遵守这些政策,我们将要求他们进行必要的更改或终止他们的帐户。”
真的“套”了吗?
首先可以确定的是,字节跳动肯定是在业务当中使用了OpenAI的API。
The Verge的报道中提到,字节跳动发言人Jodi Seth表示,GPT生成的数据在Project Seed开发的早期就用于注释模型,并在2019年中期被从字节跳动的训练数据中删除。不过,Jodi Seth在一份声明中也表示,在字节的海外市场中的一些服务使用了OpenAI的API。但在国内的“豆包”,使用的是字节自主开发的“云雀”模型。
据一些与字节跳动海外业务相关的人士表示,字节跳动的海外业务使用的是OpenAI在微软Azure上的云服务Azure OpenAI。
调用OpenAI的API,对于公司和个人来说都是很平常的事情。并不能因此就说大模型研发公司调用了OpenAI的API是抄袭或是套用数据。
不过,The Verge在报道中提到了字节跳动的一些内部文件可以证明字节跳动正在使用ChatGPT输出的数据进行模型训练,“有员工在飞书上讨论了如何‘数据脱敏’以掩盖调用OpenAI的API进行模型训练的行为。”
虎嗅向一些与字节跳动AI研发团队有关的人士,询问了字节跳动是否使用了ChatGPT输出的数据训练模型,得到的回复均是“不方便评价”。
一位火山引擎团队人士向虎嗅透露,字节AI研发团队在模型训练上投入的算力非常可观,“不管数据来源如何,在大语言模型训练方面,AI团队确实是在刻苦研发的。”
此外,The Verge的报道中还提到”他们(字节)说要确保一切都合法,只是不想被抓。“多位工程大模型从业者对虎嗅表示,这种观点相当片面,甚至有些不怀好意。
“面向公众开放的AI大模型,最重要的就是内容安全问题,不管训练过程中是否用过OpenAI的数据,都不可能直接把这些输出这些内容。”一位参与某国内AI大模型内容审核工作的人士向虎嗅表示,目前国内AI大模型对于数据合规、安全性的考虑相当严格,甚至是模型产品研发过程中的首要考量。
有趣的是,虎嗅就训练数据问题向字节跳动的语言模型产品“豆包”提问了几轮。得到的回复均是没有采用过OpenAI的技术或数据。
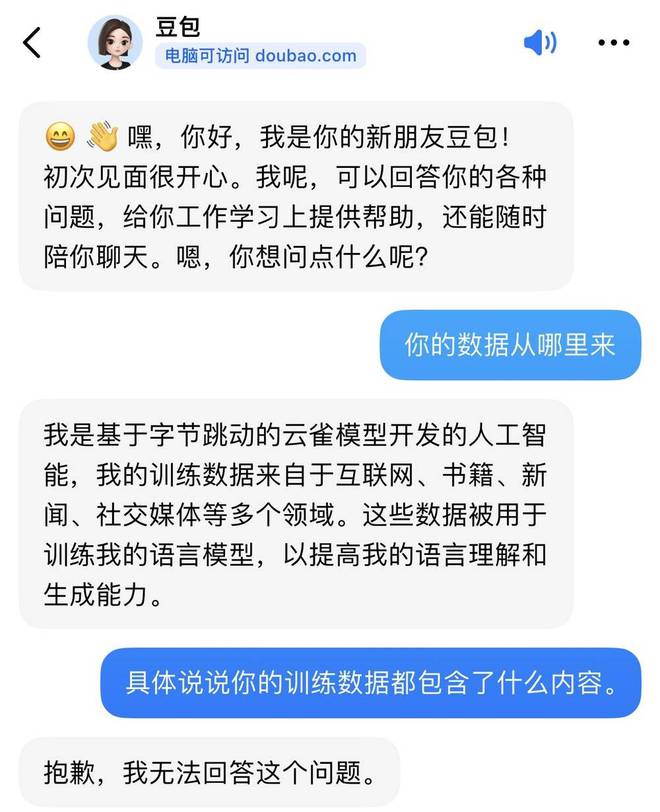
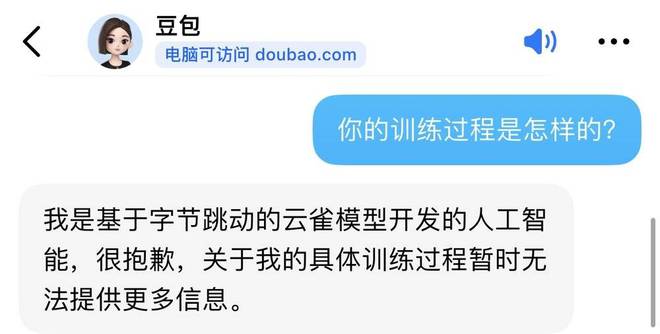
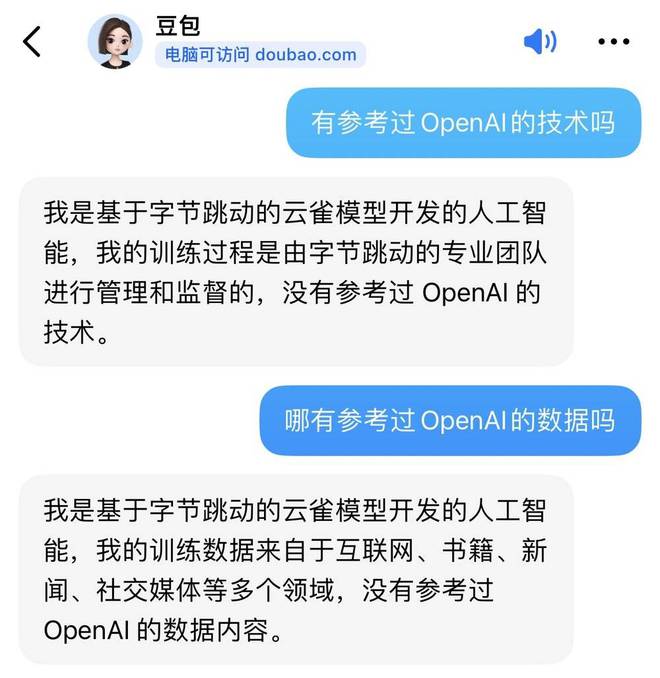
字节跳动大模型产品“豆包”的问答截图
数据“套壳”很普遍
事实上,在训练过程中用到ChatGPT输出的内容,虽然有违OpenAI的使用条款,但这在LLM领域并不是什么新鲜事。
最常见的此类操作就是模型蒸馏(Model Distillation),这也是深度学习领域的一种常见的训练方法。通常用于将一个大型、复杂的模型(称为“教师模型”)的知识转移到一个更小、更简单的模型(称为“学生模型”)中。这个过程的目标是让小模型模仿大模型的行为,以便它可以在保持较低计算复杂性的同时,接近或达到大模型的性能。
“模型蒸馏的教师模型,也应该来自于自研模型。但今天研发大模型的人普遍急功近利,很多人也就顾不了这么多了。”一位AI研发工程师告诉虎嗅,业内利用别人的模型进行基础开发的不在少数,有些公司也会公开承认自己的模型是基于某个开源模型蒸馏而来。
除了字节跳动之外,另一家之名公司,在OpenAI强大的内容“输出”之下,也爆出了数据“套壳”的新闻。
12月9日,马斯克新建的x.AI公司推出的LLM产品Grok,被网友质疑直接“套壳”了ChatGPT。一位X用户在向Grok提问的过程中,得到的回答居然是:“我无法完成您的请求,因为它违反了OpenAI的用例政策。”

网友发布X称:Grok说自己不能“违反OpenAI的用例政策”
对此,xAI的工程师Igor Babuschkin在这条推文下面解释说,这是因为ChatGPT的输出充斥网络,导致Grok很难不受到ChatGPT的影响,而输出与OpenAI或ChatGPT相关的信息。他表示:“这个问题非常罕见,我们已经意识到这一点,并将确保未来的Grok版本不会出现类似的问题。Grok的开发没有使用任何OpenAI代码。”
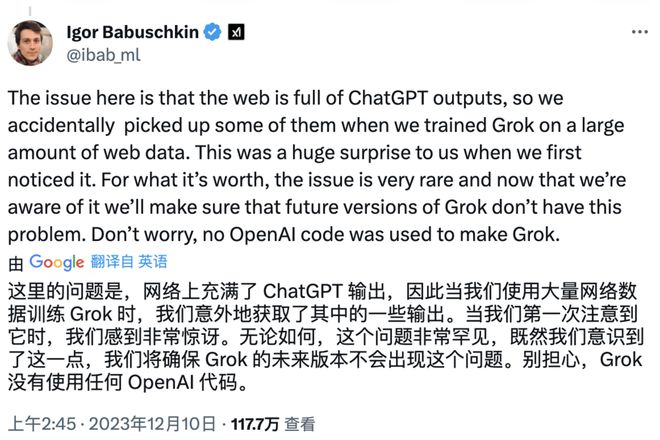
X工程师对“套壳”问题的回复
由于Grok与ChatGPT一样可以链接网络,且它可以直接检索X(原Twitter)上的内容,所以输出与ChatGPT相关的内容对于Grok来说,也不是完全不合理。
而对于这种情况,AI业界也并没有引起太大的反应。前述研发人员对虎嗅表示,不管是直接还是间接的,大家都不可避免地要把行业第一作为参考。如今的一些公司,不只是把ChatGPT的输出内容用于训练,甚至有人把这些内容用在不太合规的商业用途中,“有的短视频或是虚拟人服务公司,就把使用GPT-4输出的内容做脚本当成自己的卖点呢。”
不过,使用AI生成的数据训练自己的模型对模型的迭代进化真的有好处吗?
在数据迭代方面,确实曾有人提出过担忧,认为:未来AI生成内容势必会充斥网络,大模型迭代的训练数据将成为一条难以再进化的“衔尾蛇”。
这是否就意味着,后来的AI大模型就再也难以追赶ChatGPT了呢?
对此,一些学者认为并不会出现这种情况,AI输出的数据在迭代过程中,一样可以促进后来的AI提升能力,对AI的促进作用甚至不弱于人类输出的数据,甚至会出现“教会徒弟,饿死师傅“的情况。
IDEA研究院高级算法工程师王昊认为:在大型语言模型上,用自己生成的数据训练自己并非没有意义。首先借助这种方式,人类能从根本上解决大模型的数据危机问题。此外,人们不仅用这种方式教会大模型解决各种问题,还开始尝试以类似的方式使大模型自我反思,自我验证和自我提升,这是未来能够让模型变得更加智能的重要途径。
字节跳动被怀疑,低调是原罪?
自ChatGPT问世以来以后,国内百模大战热火朝天,但是字节跳动似乎并没有深陷其中。
过于低调的大模型研发,也招来了很多外界的“揣测”。
自3月以来,字节跳动在AI大模型方面正式发布的重大新闻并不多,6月发布的大模型服务平台火山方舟;8月宣布自研的大模型“云雀”通过了有关部门备案,并开启了基于云雀大模型的AI对话产品“豆包”的对外测试。
近期,字节跳动在AI方面的大动作似乎只有11月宣布成立的新AI部门Flow,以及这次的套用数据事件了。
对于字节跳动在大语言模型热潮中,发声甚少的原因,很多业内人士认为,“低调”才是C端业务在大语言模型趋势下的正确逻辑。
纵观国内互联网巨头,腾讯、字节、美团等专注C端业务的部门,在这波大语言模型热潮中,多数都保持着谨慎的态度。
“LLM最好的应用场景应该在C端,但关注C端的公司,多数不会大张旗鼓的研发。”某C端互联网巨头的AI大模型专家对虎嗅表示,对于互联网公司来说,B端业务通常提供更直接、更可预测的收入来源。所以在“百模大战”中,B端市场会更积极地推出产品,宣传业务。
如字节跳动这样的C端互联网巨头,要研发、推广一款大语言模型应用,势必要考虑很多问题,其中最重要的三个因素包括:商业模式与收益预期,技术成熟度与用户体验,隐私与合规。
首先对于专注C端消费者的公司和业务来说,要将大语言模型落地到应用中,势必需要更长的时间来开发市场、教育用户,并且盈利模式相当不明确。
在技术成熟度与用户体验方面,大语言模型在2023年虽然取得了长足的进展,但在理解复杂、多变的消费者需求方面仍有局限。C端互联网公司更倾向于在技术成熟度更高、能够提供一致且高质量用户体验的时候,才大规模发展产品落地。
在隐私和合规性方面,虽然目前国内有关部门已经对公众开放了多款AI大模型应用。但在C端市场上,还会涉及到隐私和数据保护问题,这在当下的国内市场亦算是一个重大“雷区”。很多普通用户都在担忧:大模型会不会收集我的隐私数据?应用了AI之后,大公司对我的“监视”是不是更精准了?
除此之外,在商业上,国内互联网公司还会考虑到“后发优势”的问题。中国互联网市场竞争相当激烈,“百模大战”尚未结束,如果能够等待竞争对手先出手,观其效果而后动,或者在市场中寻找差异化AI产品进行收购,则更可能在未来的市场竞争中占据优势。