2023太原站wtt常规挑战赛比赛时间是从11月7日开始吗?
2023-10-30
更新时间:2023-10-20 16:08:58作者:橙橘网

西风 发自 凹非寺
量子位 | 公众号 QbitAI
清华开源通用智能体XAgent,登上GitHub热榜,狂揽1400+星。

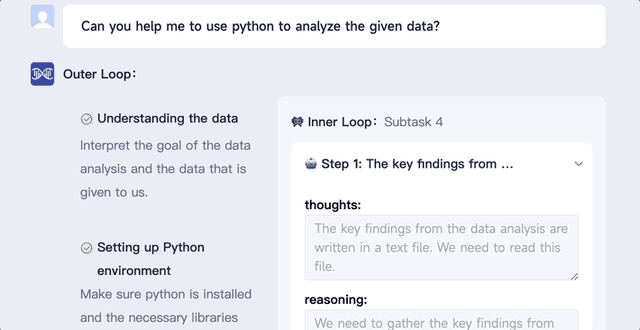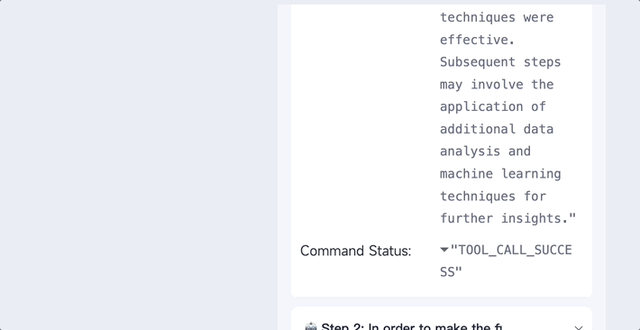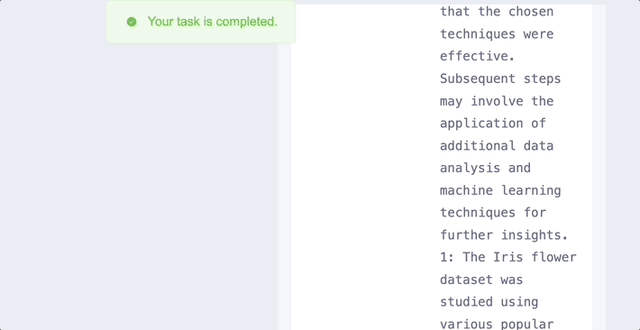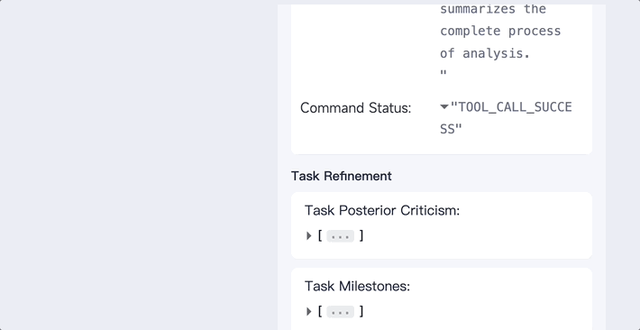
各种任务都能做,让它使用python来分析给定的数据,分分钟搞定:
数学题也难不倒它:

编制最有影响力的心理学读书清单,并对每本书做简要总结这种操作就更不在话下:

(上图中的翻译均为机器翻译)
通过展示可以看到,XAgent在回答问题时会分条缕析,逐步给出回答,这是开发专门为其设计的双循环机制。
这种设计下,XAgent的自主性非常高,处理复杂任务也“得心应手”,关键安全性也很高。
在各项基准测试下,XAgent表现都完全优于AutoGPT、GPT-4。
更多细节我们接着往下看。
将一个数据包上传到XAgent,让它分析数据并生成一个报告,它就能迅速将任务分解为数据理解、验证Python环境、编写数据分析代码、编写报告4个子任务。
最后绘制出来的图是这样婶儿的:

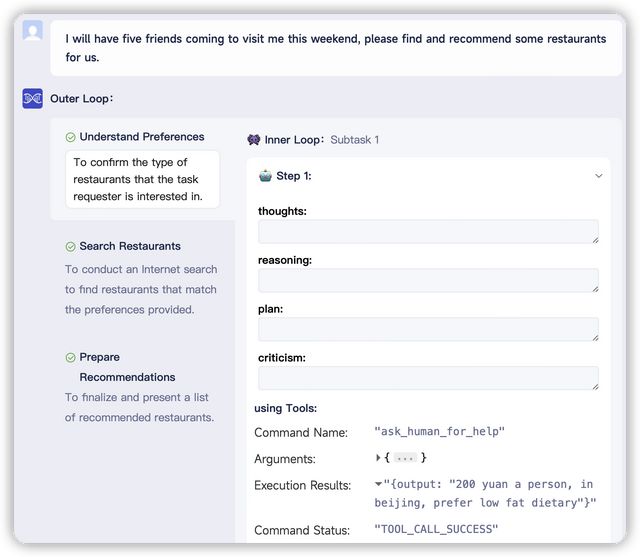
再来让XAgent推荐一些适合好友聚会的餐厅,但这次故意不提供具体细节。XAgent识别到提供的信息不足,立刻采用了“请求人类帮助”工具,让用户介入表明自己喜欢的位置、预算限制、烹饪偏好、有无忌口等。
如此一来,XAgent就能生成一份定制化的餐厅推荐名单。
此外,XAgent处理起复杂任务也是有两把刷子在身上的,比如训练模型。
开发者展示了一个希望XAgent分析电影评论并评估特定电影周围公众情感的情景。收到这一指令,XAgent迅速启动下载IMDB数据集,训练一款先进的BERT模型。
拥有了这个训练有素的BERT模型,XAgent就能够轻松应对电影评论的复杂细节,提供关于公众对各种电影看法的见解性预测。

总的来说,开发者表示XAgent具有五大特点:自主性、安全性、可扩展性、GUI、人机协同。
自主性是指XAgent可以在没有人类参与的情况下自动解决各种任务。
而安全性则是因为它的所有行为都被设计限制在一个docker容器(ToolServer )内,不用担心主机环境会受影响。
docker容器内包含了可以写入、读取和修改文件的文件编辑器,可运行Python代码的Python笔记本,可搜索和访问网页的网页浏览器,还有一个bashshell工具以及Rapid API。
所以,使用者也可以轻松地添加新工具来增强智能体的能力,甚至打造一个全新智能体。
开发者还为用户提供了友好的图形用户界面来与XAgent交互,当然也可以使用命令行界面。
人机协同这方面主要是指XAgent不仅有能力按照人类的要求来解决复杂的任务,而且在遇到挑战时还可以寻求用户帮助。

能够拥有这些特点,还要得益于XAgent的核心设计。XAgent主要由三大部分组成:
设计上,开发者刻意避免将人类的先验知识注入到XAgent系统设计中,而是赋予了智能体自己规划、决策过程的能力,进一步发掘智能体的潜力。
另外,XAgent框架设计还采用了双循环机制:外循环(Outer-Loop)用于高级任务管理,内循环(Inner-Loop)用于低级任务执行。

外循环使智能体能够识别总体任务,然后将其划分为更小、更具可操作性的子任务。相比之下,内循环过程作为详细的执行器,专注于处理被划分的任务。
开发者表示:
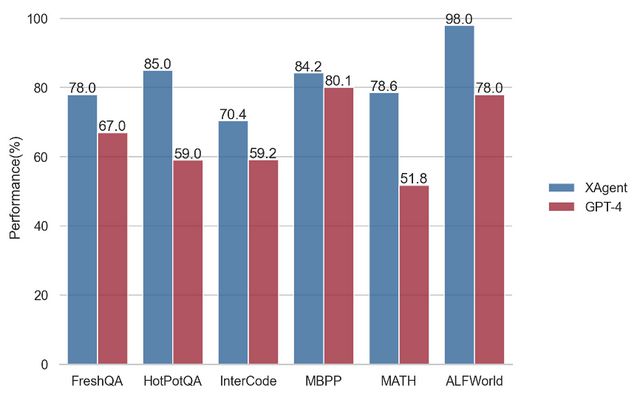
开发者还对基于GPT-4所打造的XAgent进行了一套基准测试,主要测试XAgent推理、规划和使用外部工具的能力。
测试内容包括:在FreshQA和HotpotQA上测试Web搜索问答能力;在MBPP上测试Python编程能力;在MATH上测试数学推理能力;在InterCode上测试交互式编码能力;在ALFWorld上测试文本游戏中的具身推理。
以下是与原版GPT-4的比较,XAgent全面优于GPT-4:
考虑到缺乏合适的针对AI智能体的高质量基准测试,开发者还手动策划了50条复杂的指令,可以分为5个类别:搜索与报告,编码与开发,数据分析,数学和生活助手。
然后将指令它们输给了XAgent和AutoGPT,并邀请了多位专家来评估对XAgent和AutoGPT输出结果的偏好(胜率)。

结果XAgent全面取胜,不仅在传统的AI基准测试中表现出色,而且还在处理复杂指令方面表现出卓越的适应性、效率和精度。
GitHub链接:https://github.com/OpenBMB/XAgent