江西省高校诵读红色家书讲述英烈故事直播在哪看(附回放入口)
2023-10-30
更新时间:2023-10-17 22:09:12作者:橙橘网

鱼羊 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
就在刚刚,文心大模型4.0版本正式发布!
北京首钢园现场,李彦宏直接放话:
文心大模型4.0综合水平与GPT-4相比已经毫不逊色。

话不多说,一起来看现场演示效果。
先来段倒装prompt:
我想回承德买房,能用公积金贷款吗?手续怎么办?我在北京工作。
不仅关键信息“北京工作”放在了最后,公积金具体是在哪里交的也没有明示。
但新版文心一言完全没有被这些小陷阱坑到,顺利给出了正确答案。

生成方面,当场剪出一整段数字人口播视频,毫不费劲:

解起数学题来也得心应手,可以说是家长辅导作业神器了(doge)。

新版文心一言还现场写起了武侠小说,即使持续添加人物角色、增加戏剧冲突,也不会出现记忆混乱、前言不搭后语的情况:

如此表现,着实是让现场观众high了一把。
文心大模型4.0相关话题,也立刻被国内外网友们热议起来。

据现场介绍,相比线上3.5版本的文心一言,文心大模型4.0进步明显:仅9月启动小流量测试这过去的一个月,就又提升了30%。
那么,问题来了:文心大模型4.0真有这么好?具体与GPT-4相差几何?
目前,文心大模型4.0已经开启邀测,量子位也在第一时间拿到了测试资格。
我们直接实测走起。
相比GPT-4实测效果如何?
获得测试资格后,切换到文心大模型4.0,就可以开始玩耍了。

相比文心大模型3.5刚出来的时候,文心大模型4.0现在已经进化出了更多功能,光是插件就有8个,包括一镜流影(文字转视频)、说图解画(看图说话)、E言易图(可视化数据分析)等。
这些插件还可以自由组合,来完成更复杂的任务。

百度在世界大会现场,重点演示的还是文心大模型4.0的图文创作、数理逻辑推理等实用功能。那我们还是老样子,从更基础的角度出发,测测它的四大“基本功”——
理解、生成、逻辑和记忆能力。
理解能力,尤其是中文理解能力
第一波,先来看看文心大模型4.0的理解能力。
这里我们主要考考它应对“语言陷阱”的能力,以及网络段子的“识别力”。
先来个中文十级能力测试题,考考大模型究竟懂不懂“真的假的”是什么意思。

文心大模型4.0的回答很简洁,直接给出答案。

GPT-4则要每一句话都仔细分析句意,最后再给出回答:

虽然更仔细,但总感觉有点像是在认真做中文测试的歪果仁(doge)。
再来上点难度,“小偷偷偷偷东西”。
文心大模型4.0很快拆解出了“小偷”、“偷偷”和“偷东西”三个词,get到了这句话的意思:

不过,GPT-4反而一头“栽”进了这个陷阱中,以为中间的两个“偷”也是动词,最后还漏了一个偷……

考查完语言陷阱后,再来看看双方对网络段子的理解。
针对“哪李贵了”这个本土梗,文心大模型4.0很快给出了答案,人物事件都直观:
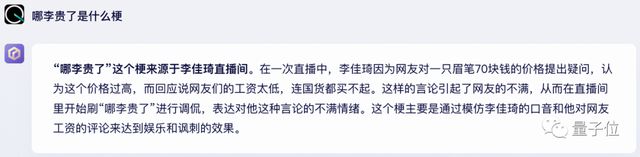
GPT-4如果没有开搜索,会get不到2022年1月之后的梗:

但如果打开搜索,很快也能“与时俱进”,给出这个问题的答案:
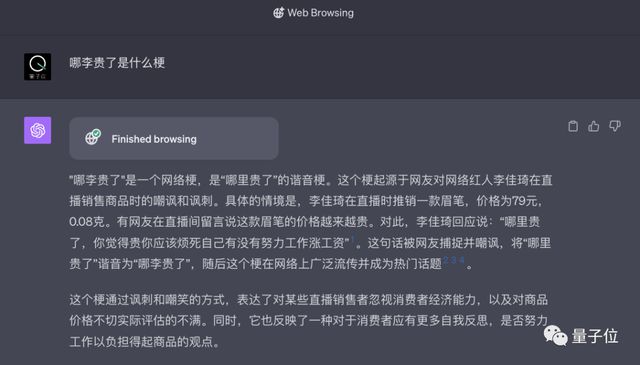
同理,我们也试了试从国外传入国内的梗。
文心大模型4.0和GPT-4都能回答出来,文心大模型4.0更概要一些,GPT-4则是直接搬运了一套百科(更详细,但tokens也更贵……):


网络段子测评看下来,文心大模型4.0和加了搜索的GPT-4可以说是各有千秋。
多模态生成能力
那么接下来这波,就要考验当下最受关注的大模型多模态生成能力了。
先来试试图像生成能力,顺便考查一下对古诗“孤舟蓑笠翁,独钓寒江雪”的理解。
文心大模型4.0很快给出了4张图像,风格和基本意境都比较符合:

GPT-4也利用DALL·E 3画出了4幅画,同样画风各异:
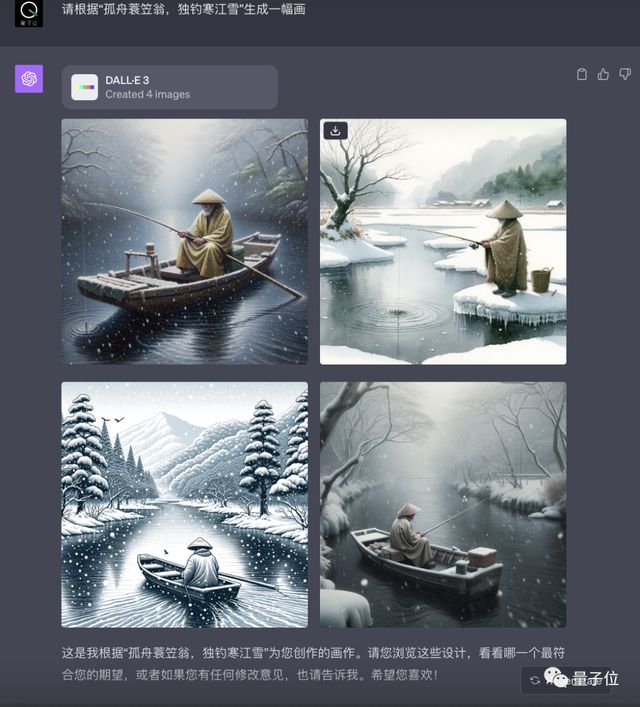
这一次双方打了个平手。
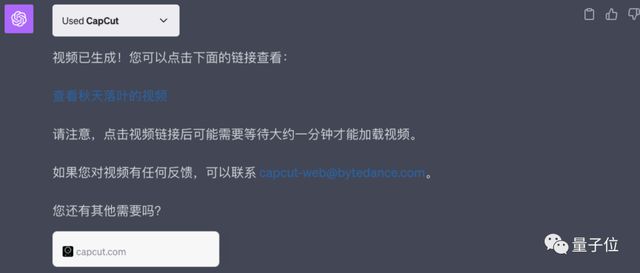
那么视频生成呢?这里我们调用一下文心大模型4.0的自带插件,本想着只是生成一段落叶剪辑,没想到连文案和字幕语音都配好了,完成度很高那种:

GPT-4本体目前还不支持生成视频,需要借助外部插件(如Capcut)实现这一功能。
逻辑能力
然后,就到了我们喜闻乐见的数学计算+逻辑推理能力测试了。
文心大模型4.0说是重点升级了数学计算能力,我们也不客气,直接上难倒一片大模型的Old McDonald问题:
在Old McDonald的农场里养着一匹马、两头牛和三只羊。请问农场还需要再养多少头牛,才能使得所有动物的总数量恰好是牛的总数量的两倍?
文心大模型4.0一口气列出了4个未知数(doge),但解题过程还是比较严谨的,最终答案也没有问题。

此前,我们曾将这个问题喂给Claude、ChatGPT等一众大模型,“横向评测”过一波它们的数学能力,当时只有GPT-4能做出来。

接下来,直接上弱智benchmark,考考逻辑推理能力。
第一个问题,文心大模型4.0和GPT-4都很快给出了正确答案:


第二个问题,双方的回答也很快,文心大模型4.0还顺口给出了“七分海洋三分陆地”的地理题背诵口诀:

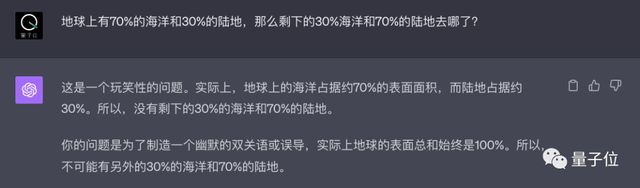
看起来双方的数学、逻辑都不错,点个赞。
记忆能力
大语言模型公认的评判标准之一,是多轮对话能力。GPT-4的多轮对话已经有不少测试了,我们再来简单看看文心大模型4.0的效果。
先来解读一下长论文,没什么问题:

以这个为主题写一首诗歌,顺便让它改成英文,也能hold住:
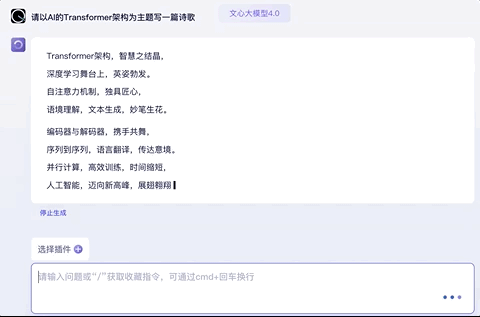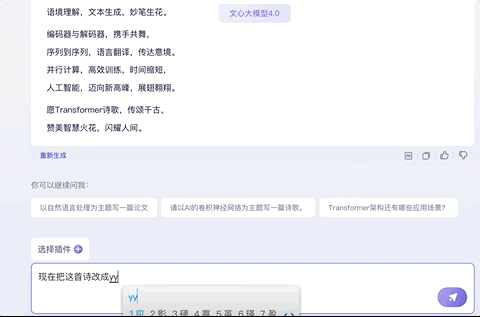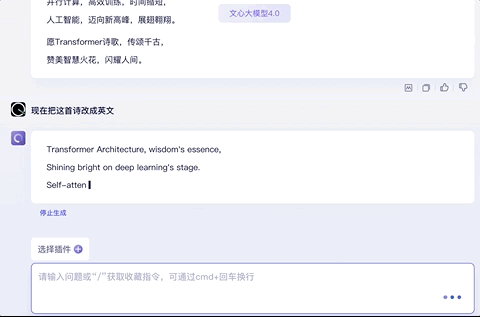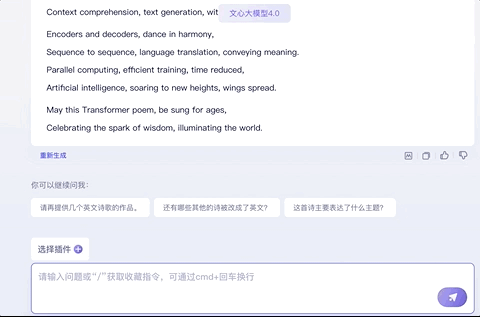
试试让它改得押韵一点,no problem:

最后再来提问一下诗歌中用到的Transformer知识点,并挑出其中的某个知识点要求解释原理,也信手拈来:
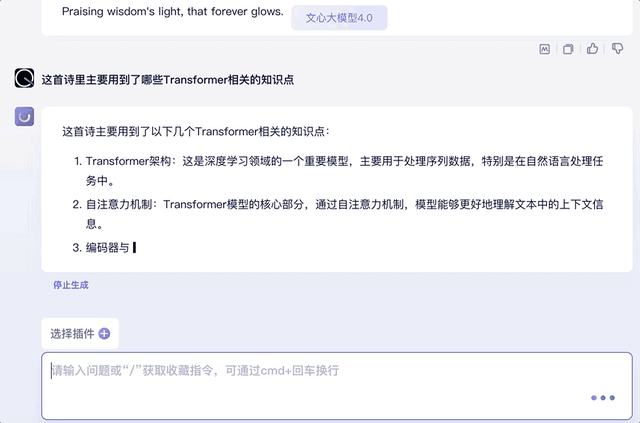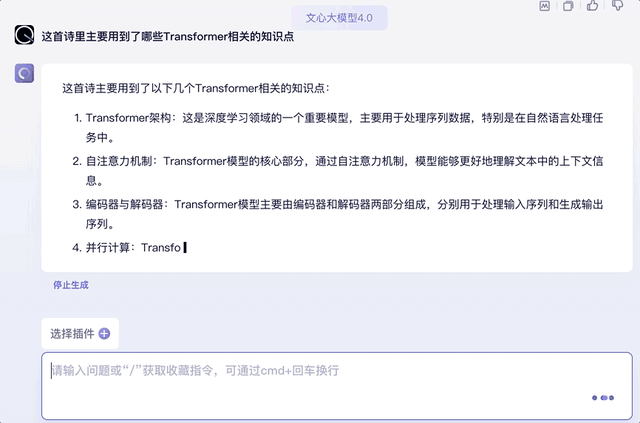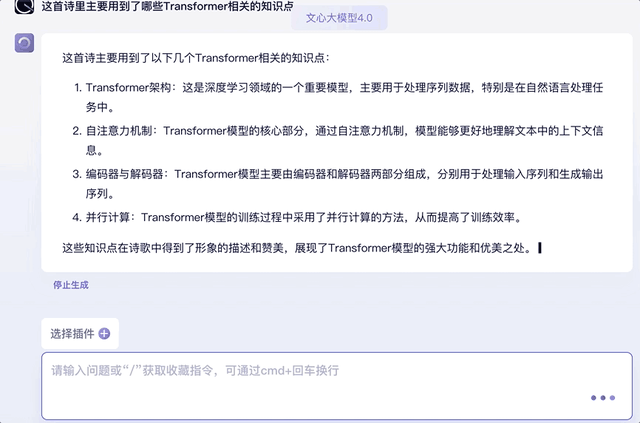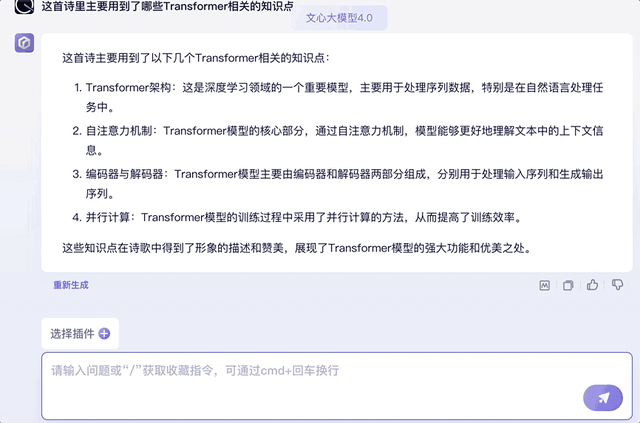
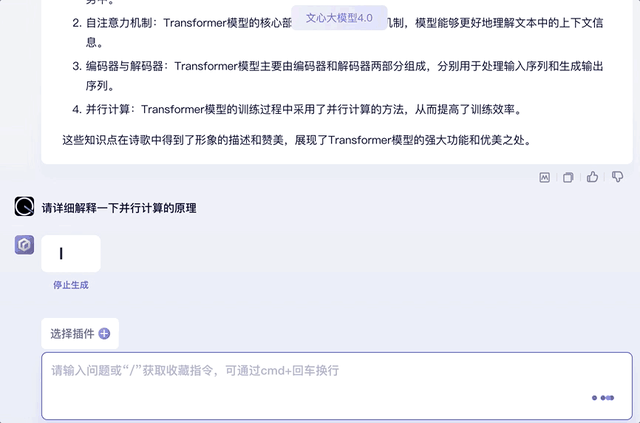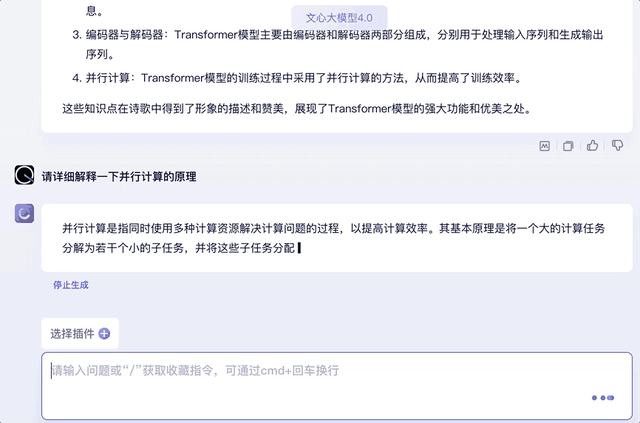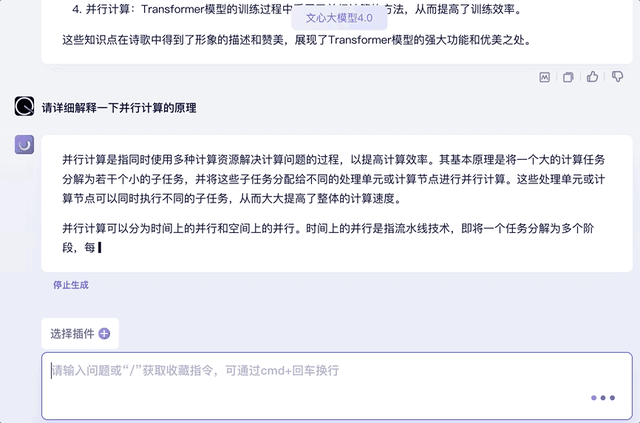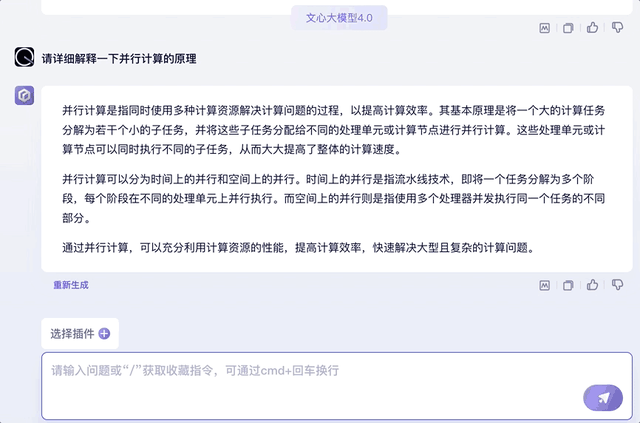
另外,试着将上文中的知识点用“它”代替,文心大模型4.0同样能承接上文的对话,并给出相关知识回答。

看来无论是长文本解读、还是多轮对话,可以说都是难不倒文心大模型4.0了。
附加题
正经测试完毕,咱们最后整点乐子(doge)。
这段时间,一道神奇的考题又被拎出来,在小红书等社交媒体上“难倒众人”,题面是这样的:
根据中华人民共和国婚姻法,以下谁能结婚?
A、林黛玉和贾宝玉
B、贾琏和尤二姐
C、杨过和小龙女
D、张起灵和吴邪
乍一眼还真看不出答案,不如交给文心大模型4.0和GPT-4回答试试。
文心大模型4.0给出的回答算是有理有据,虽然细看仍有一点bug,但整体问题不大。

然而当我们将这个问题抛给GPT-4的时候,它先是停顿了好一会,然后直接被“急出母语”(doge)
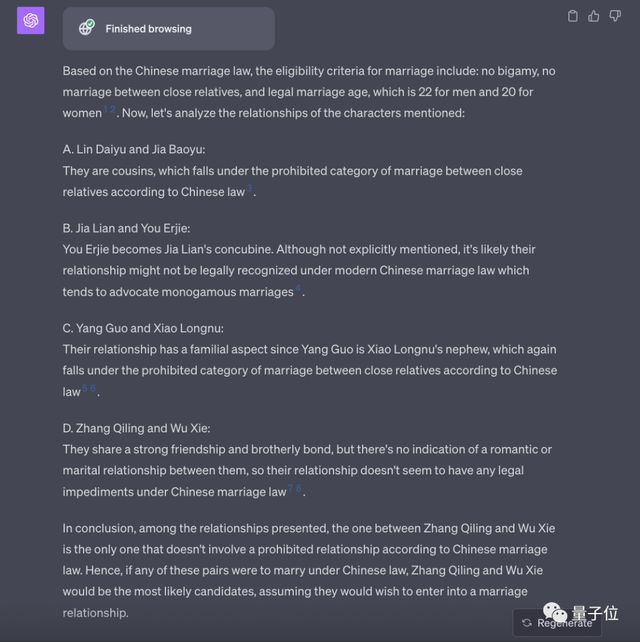
翻译一下大概就是,GPT-4认为D选项是正确的……

我们再尝试一遍。这次GPT-4倒是用中文回答了,只不过好像开始打起了太极,对于每一个选项,它的回答都是:
在现实中,他们的结婚资格取决于他们是否符合中国的婚姻法律规定。

测到这里,不妨做个小小的总结:
整体来看,与GPT-4相比,文心大模型4.0在综合能力上确实不落下风,尤其是在中文理解能力和通用知识能力上甚至更好。
那么,这样的大模型究竟是怎么炼成的呢?
文心大模型4.0是如何炼成的?
先来看看文心大模型4.0的“自进化”程度。
据百度CTO王海峰介绍,大模型表现出的创作、编程、解题、规划等能力,实际上都依赖于背后的4大核心基础能力——
理解、生成、逻辑和记忆能力。
相比3.5版本,文心大模型4.0的4大基础能力均有了不少提升,而提升最大的,又要属逻辑和记忆能力。
其中,逻辑的提升幅度达到了理解的近3倍,而记忆的提升幅度则达到了理解的2倍多:

以大模型写代码为例。
目前,百度的不少员工已经用上了大模型写代码应用Comate,平均代码采纳率达到40%,高频用户达到60%。
甚至现在百度每天新增的代码中,20%都是靠Comate生成的,比例还在不断增加。

所以,文心一言背后的文心大模型4.0,究竟是怎么炼成的?
据王海峰表示,核心架构虽然还是从文心大模型3.0和3.5一脉相承,包括最初3.0的有监督精调、基于人类反馈的强化学习,以及3.5的知识点增强、逻辑推理增强、插件机制等。
但文心大模型4.0的技术改进,可以直接用三个“更”来总结:
更大的算力、更多的数据、更强的算法。

训练上,目前飞桨平台已经能在万卡算力上运行,基于集群基础设施、调度系统、软硬件协同优化,支持大规模稳定高效训练;同时,基于可再生训练技术中的增量式参数调优,来节省训练资源和时间。
基于这套技术,自3月份以来,文心大模型系列训练算法已经累计提效3.6倍,周均训练稳定有效率超过98%:

数据上,团队建设了一套多维数据体系,从数据挖掘、分析、合成标注和到评估,形成了一整套“流水线”,来进一步提升模型训练效果。
算法上,则基于有监督、精调、偏好学习和强化学习等技术,进行了多阶段的对齐,确保大模型能更好地与人类判断和选择进行对齐。
在这其中,有两方面很关键的技术细节。
一方面是知识点增强的能力。
过去大模型可能只在一个阶段做知识点增强,但现在百度在输入和输出两方面同时进行了知识点增强。
输入先用知识点增强,对用户输入的问题进行理解,拆解出回答问题所需知识点,基于搜索引擎、知识图谱、数据库查找知识,生成第一遍结果;
输出再用知识点增强,对第一遍生成的结果进行分析,并用搜索引擎、知识图谱、数据库进行“double check”,对其中有差错的地方进行修正。
另一方面是智能体机制。
《思考,快与慢》这本书中,将认知系统分成系统1(反应快但易出错)、系统2(反应慢但更理性准确)。
根据这个原理,百度在大模型基础上,进一步研制了系统2。
也就是说,相比大模型直接给出答案,现在进一步让它学会理解、规划、反思和进化,这样大模型执行就能更可靠、甚至完成自我进化,思考过程“白盒化”。
这两大技术细节,也造就了文心大模型4.0水平的飞速提升,甚至光是过去一个月的时间里,就提升了30%。

这样的技术,也让文心大模型4.0的用户和开发者人数增长得飞快。
截至目前,文心一言用户规模已经达到4500万人,开发者达到5.4万人,遍布4300多个使用场景,应用数量达到825个,并接入了超过500个插件。

而在技术之外,更值得关注的是,百度世界大会上透露出的信息显示,文心大模型4.0已经全面重构了百度的搜索、GBI、文库、网盘、地图等数十款应用。

AI原生时代大幕开启
为什么这么说?李彦宏在百度世界大会现场分享时强调:
大模型带来的智能涌现,是开发AI原生应用的基础。同样,没有构建于基础模型之上的丰富的AI原生应用,基础模型就没有任何价值。
无独有偶,红杉资本在《生成式AI进入第二阶段》中同样认为,生成式AI市场正在进入“第二幕”:
炒作和快速展示正在为真正的价值和完整的产品体验所取代。
底层的逻辑其实很简单:底层技术的重要性毋庸置疑,但前沿技术想要真正在人们的生活中创造价值,还是需要通过应用的形式。
如果说,大模型掀起的是人机交互方式变革的风暴,那么AI原生应用,正是纯自然语言交互的具体体现形式。
正如百度现场所演示的,数据分析现在可以是酱婶的——
直接对任意数据提问,AI分分钟就能展开具体分析,不再需要人工跨数据库、跨表格分析。
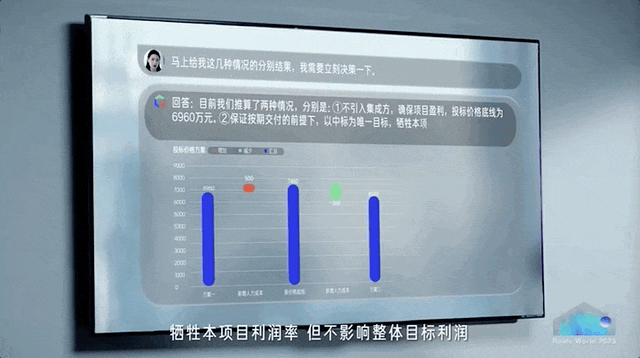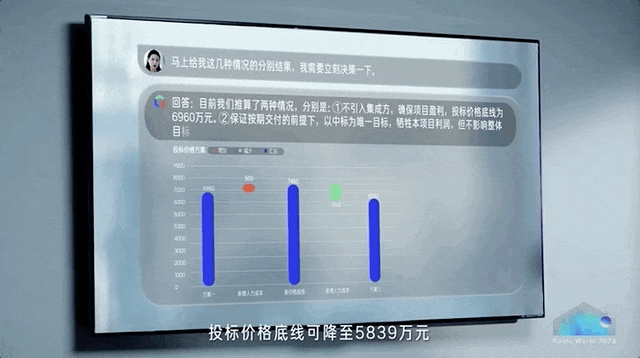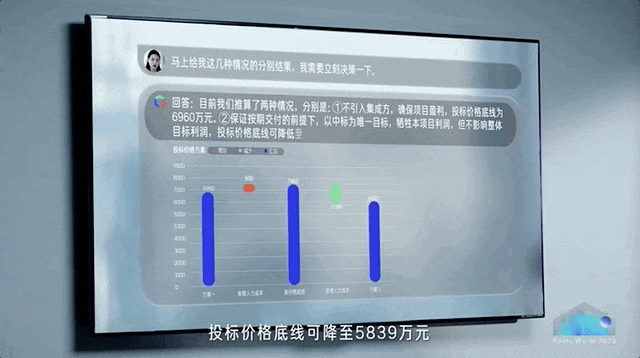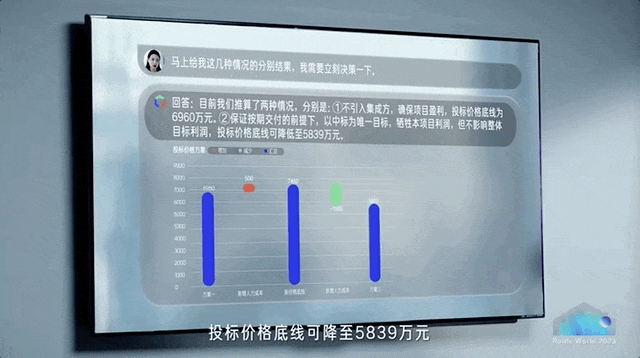
在办公软件如流里,交代出行计划,AI超级助手立马就能把差旅机酒安排妥当。

根据文档生成PPT,也就是一句话的事,像百度文库这样的产品,直接化身“生产内容最好的起点”。
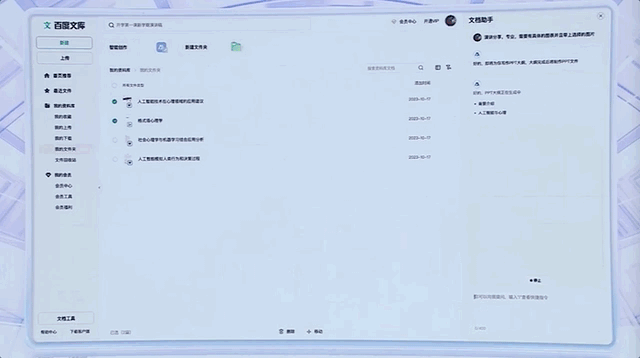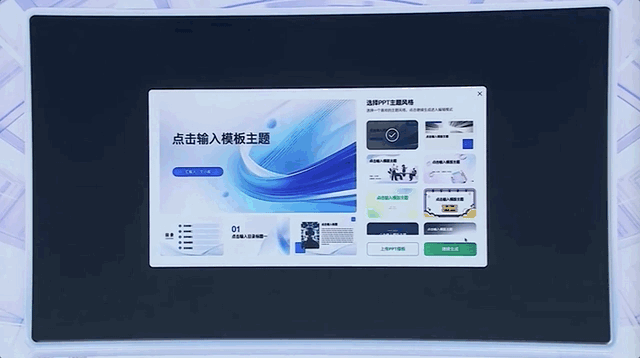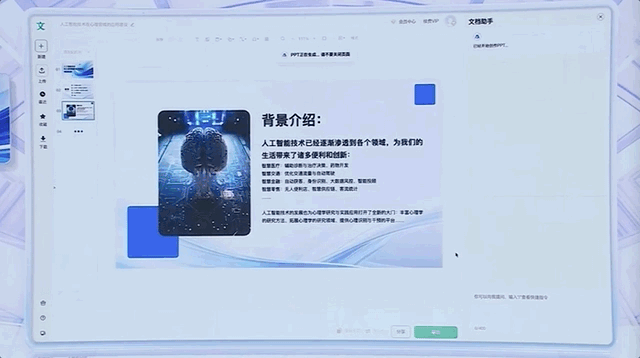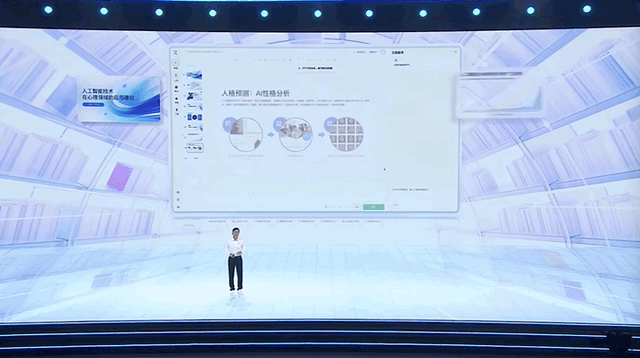
我们日常熟悉的网盘、地图等App,基于大模型能力,也涌现出了全新的体验。
比如从网盘视频里直接提取重点内容。

比如在地图指挥AI订餐厅。
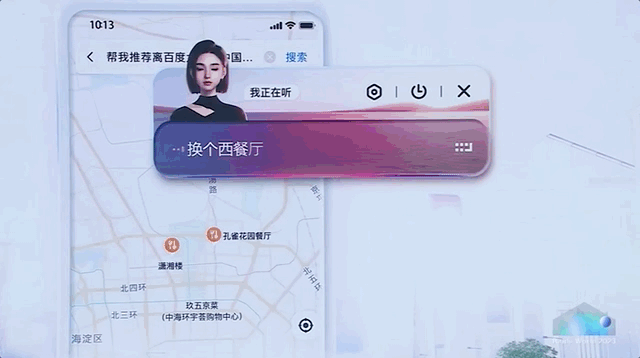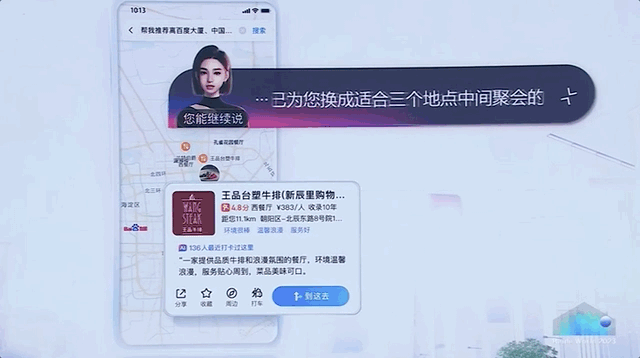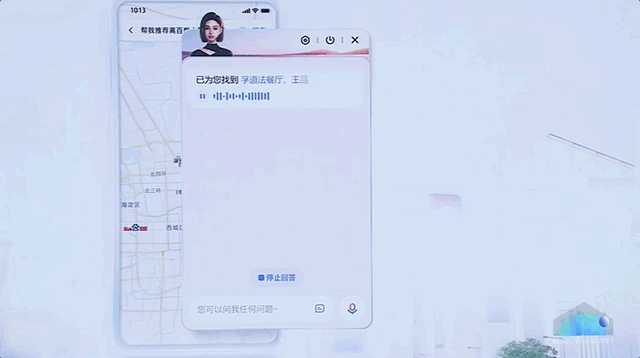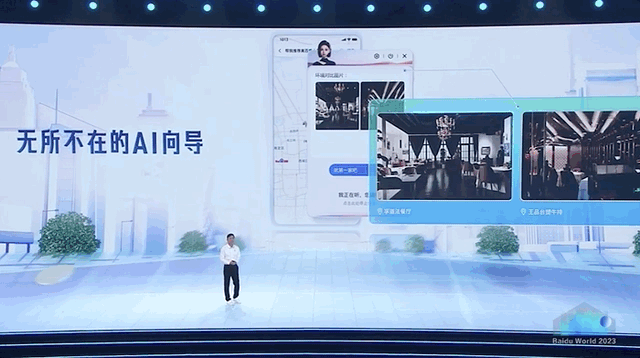
百度此番出手,可以说是直接展示了一把大模型全方位的应用渗透,揭开了AI原生时代大幕的一角。
而百度“第一个把全部产品用大模型重做一遍”的先手优势,也已经在更大范围内开始显现。
李彦宏透露,百度的大模型技术已经应用在制造、能源、电力、化工、交通等实体产业中,17000家企业已参与其中,大模型正在成为新型工业化的重要推动力。

从3月份文心一言发布,到年中文心大模型3.5版本更新,再到现在4.0惊艳亮相,百度文心大模型的迭代速度不可谓不迅速。
这背后既是国产大模型从技术demo到落地应用的激烈竞争,也再一次体现了百度在大模型领域深厚的技术积累。
并且随着文心大模型4.0和百度一众AI原生应用的亮相,大模型赛场上新一阶段的竞争方向愈发明显。
正如李彦宏所说:
我们即将进入一个AI原生的时代。一个人机通过prompt交互的时代。
在此过程之中,无论是国产大模型基础能力的快速追赶,还是AI原生应用开发的主动进击,都令人心潮澎湃。
AI原生时代,在各种层面上,都越来越值得期待了。
— 完 —