江西省高校诵读红色家书讲述英烈故事直播在哪看(附回放入口)
2023-10-30
更新时间:2023-10-16 22:09:13作者:橙橘网


论骚操作,硅谷恐怕没有CEO能比得上黄仁勋。
去年,黄仁勋向微软、谷歌和亚马逊这些云计算厂商提出了一个计划:这些厂商都有很多搭载了英伟达GPU的服务器,由英伟达租用这些服务器,然后让英伟达的工程师对其进行“优化”,再以英伟达的名义租给普通的AI企业,从中赚取差价。
说简单点,以前微软会直接把云服务卖给中小公司,现在由英伟达进来当中间商。当然按照英伟达官方的说法,此举是为了“向云计算厂商展示在数据中心配置GPU的正确方法”[1]。
服务器还是那个服务器,但经过英伟达“优化”后,客户就从微软优化到英伟达了。但就是这样一个匪夷所思的提议,除了亚马逊之外,各大云计算厂商居然都同意了。
2023年3月,英伟达正式上线云计算服务DGX Cloud。事实证明,经过英伟达工程师的优化后,DGX Cloud在训练大模型时表现得的确更好;在此基础上,英伟达还破例允许短期租赁。仅仅半年时间,英伟达就拿下了软件公司ServiceNow等大客户。
科技公司愿意配合英伟达骚操作的真实原因,可能还是因为英伟达手中握有大模型时代最稀缺的资源——H100。
当下,几乎所有的企业都没有足够的算力。连OpenAI创始人阿尔特曼,都曾在一次听证会上无奈地表示:“如果人们减少使用ChatGPT,我们会非常高兴,因为我们的GPU非常短缺[2]。”
买了多少H100,甚至可以成为决定AI成就的关键因素。这也让英伟达有了“挟H100以令诸侯”的底气。
计算机的“稀土”
通常来说,科技企业会通过购买云计算厂商的服务,来满足算力需求。从2023年3月开始,微软Azure、亚马逊AWS等云计算厂商也先后上架了HGX H100的租赁服务,HGX H100是由4个或8个H100组成的服务器。
然而,当下供需严重失衡,云计算厂商这点H100存货已经远远满足不了市场的胃口。2023年H1的财报中,微软专门更新了一条风险因素:如果无法获得足够多的AI芯片,云计算业务可能会中断。
许多初创公司需要排队等待3-12个月,一旦友商抢在自己前面,那可能就是几十上百亿估值的损失。

HGX H100
无数“H100穷人”们,只能被迫发挥主观能动性,看谁的路子更野。
面对《纽约时报》的采访,一位创业者将H100比作“稀土”。早些时候,他跑去请求美国国家科学基金会投资自己,仅仅因为基金会底下一个项目刚好有少数空置的H100。
在硅谷,AI创业者打招呼的方式,都变成了“我认识一个有H100的家伙”——不知道的还以为在买卖毒品[4]。
GPU Utils曾测算过H100抢购潮背后具体的需求数据:
对需要自己训练大模型、追求大力出奇迹的企业来说,没有个上万块H100都不好意思出门。由前DeepMind联合创始人苏莱曼创办的Inflection AI,成立方才一年,已买了2.2万个H100;至于Meta这样财大气粗的公司,很可能会购买10万个甚至更多。
对微软Azure等云计算厂商来说,每一家也都需要至少3万个H100。而其余几家私有云,还将消耗总计约10万个H100。
测算后发现,仅美国大型科技公司和少数几家明星初创公司,需求量已达到约43万个[5]。如果再算上其他初创企业、研究机构、大学,乃至富裕国家的追逐、再加之黄牛、黑市等不可控因素,实际需求很可能远大于这个数字。然而据英国《金融时报》爆料,今年H100的出货量大约是55万个[6]。
H100之所以令人如饥似渴,其中一个核心原因在于其近乎垄断的市场地位。
面对大模型训练对极致效率的需求,H100在大多数情况下都是最优解。
MPT-30B是第一个使用H100训练的开源LLM(大语言模型),实际训练只耗费了11.6天;相比之下,使用前一代的A100训练则需要28.3天[7]。如若换成参数规模更庞大的AI,例如1800B的GPT-4,效率差异会更加明显。跑马圈地的时代,时间就是一切。
除此之外,H100在模型推理上的效率也远高于A100。尽管H100的首发价约为3.3万美元,如今二手市场价格更上涨至4-5万美元;但若将H100和A100的性能分别除以各自的价格,能发现H100的性价比实际也高于A100。

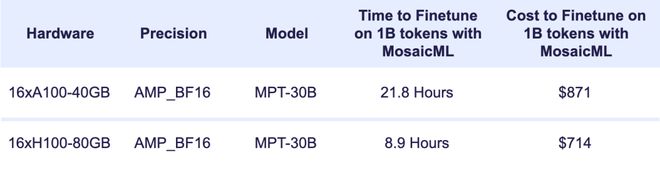
MPT-30B的具体训练、推理情况
黄仁勋说,“Buy more GPUs , the more money you save(买得多,省得多)”,似乎不无道理。
也正因为如此,即便美国限制了H/A100的对华出口,国内科技公司仍在抢购阉割版的H/A800——尽管阉割版的芯片间数据传输速度只有前者一半,意味着需要在大模型训练上花费更多时间。
除需求量庞大之外,造成H100短缺的另一个原因是产能的严重不足。
H100芯片需要使用SK海力士的HBM内存,以及台积电的CoWoS封装——两者都因过于昂贵,此前并没能大规模市场化,预备产能并不多。由于产能爬坡尚需时间,有分析师预测H100的短缺至少会持续至明年一季度,也有人认为要到明年年底才有可能有所缓解[9]。
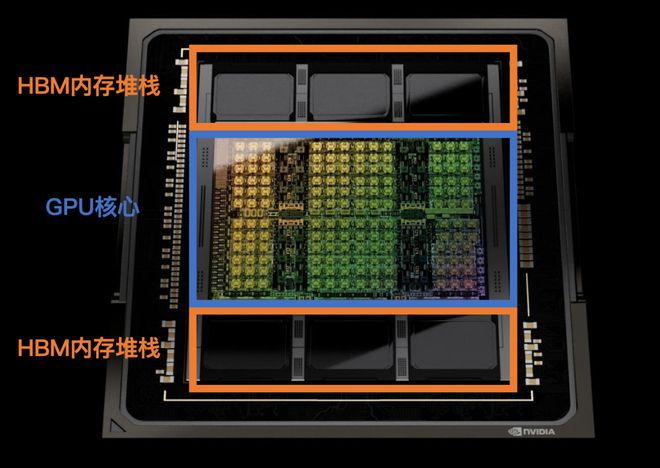
H100内部结构
H100的空前盛况,让黄仁勋在短短一年时间内体验了一回坐过山车的感觉。
去年二季度,消费市场萎靡不振加上挖矿企业扎堆倒闭,英伟达交出了一份不及格的财报,“GPU滞销,帮帮我们”的表情包一度遍地都是。一年之后,黄仁勋成功向资本市场展示了什么叫“反向暴雷”,同比营收暴涨854%,大幅超出了最乐观分析师的预测。
巅峰换来了漫天的吹捧,但黄仁勋心里清楚,英伟达的头上一直悬着一把剑。
不可避免的战争
今年8月,传奇工程师吉姆·凯勒对媒体评论道,“我不认为GPU是运行AI的全部,世界憎恶垄断[11]。”
此番发言虽有给自家AI芯片打广告之嫌,却也是业界的共识。
事实上,那些购买了最多H100的大型科技公司,基本都不太“安分”:微软、谷歌、Meta,或多或少都尝试过自研AI芯片。
这让英伟达面临着一个异常尴尬的处境:在AI芯片领域,自己与“大客户”之间,未来几乎必有一战。
大型科技公司们选择自研AI芯片,最初都源于一个非常质朴的需求——省钱,其中最典型的便是谷歌。
早在2014年,谷歌已启动了自研芯片计划。彼时,OpenAI的首席科学家伊利亚还在谷歌工作,打造出了一套颇具颠覆性的AI模型。该模型脱胎于伊利亚的“大力出奇迹”理念,只需要灌入足够多且正确的数据,它便能更好地完成翻译、语音识别等工作。然而待到实际应用时,谷歌却犯了难:
如果将AI服务安装至10亿多台安卓手机中,哪怕每个人每天只使用3分钟,谷歌都需要2倍于当前数据中心的算力。当时谷歌已经建了15个数据中心,每个造价上亿美金,“超级加倍”显然不切实际。
最终,谷歌自研出了性能更强、功耗更低的TPU,大大提升了单个数据中心的算力供应,以一种更经济实惠的方式解决了算力难题。

引入了TPU的数据中心
TPU的出现,令黄仁勋如坐针毡,开始了“爆改GPU”,很快在性能上实现了反超,其最新成果便是H100。不过,H100的售价实在过于昂贵。
如果按重量售卖H100,那么其每盎司售价将达到黄金的一半;即便对地球上最赚钱的科技公司而言,这笔“英伟达税”也堪称天文数字。
然而,H100的实际制造成本并不高。据金融咨询公司Raymond James测算,H100的成本约为3320美金,仅占首发价的1/10,黄仁勋含泪赚10倍[12]。
自研芯片的经济收益毋庸置疑,但除此之外其实还有另一个好处:垂直整合打造差异化。
堆叠算力不是简单的往车里加汽油,需要考虑软件适配性、自身业务需求等一系列问题。例如AI所使用的深度学习框架有多个派别,谷歌是TensorFlow,Meta用的PyTorch,而百度则有PaddlePaddle,硬件需要根据不同框架做适配。
专门定制的AI芯片,可以更加紧贴自身AI业务的需求。所以Meta在今年又重启了自研芯片计划,针对PyTorch框架定制了全新的MTIA芯片。
对大公司来说,考量芯片的核心其实不是算力,而是“单位美元提供的算力”,也就是成本。谷歌的TPU和特斯拉的Dojo都证明了,定制服务的成本是可以接受的。
眼下,“反抗的星火”已经点燃。据外媒爆料,大型科技公司的云计算团队,已开始频繁劝说客户改用其自研芯片,而不是英伟达的GPU。英伟达固然是目前为止绝对的赢家,但没人知道平衡什么时候会被打破。
不过,面对这场不可避免的战争,英伟达也留了后手。
挟H100以令诸侯
英伟达打出的第一张牌,叫CoreWeave。
CoreWeave成立于2017年,最初是一家以太坊挖矿公司,后来转型做起了云计算业务。据CoreWeave创始人透露,2022年公司收入为3000万美金,仅有微软Azure的1/1133,在硅谷几乎没什么存在感。
然而到了2023年,CoreWeave突然一夜成名,接连签下Inflection AI和Stability AI两个大客户,年营收预计将达到5亿美金,一年翻16倍。除此之外,微软甚至决定在未来几年花费数十亿美金购买其服务;其中仅2024年的订单,已有20亿美金。
改变CoreWeave命运的贵人,正是英伟达。
今年4月,英伟达参与了对CoreWeave的投资;但比起美元,英伟达还给了它一项更稀有的资源——H100。CoreWeave是全球第一家上线HGX H100租赁服务的云计算企业,比微软Azure还要早一个月。

CoreWeave三位创始人
这番安排,其实是黄仁勋的有意为之。
H100近乎垄断的市场地位加之严重短缺的现状,让英伟达手中多了一层权力:他可以自由决定优先供货的对象。
相比自己跟Big Tech们同床异梦的塑料友谊,CoreWeave和英伟达是实打实的革命战友。因此,英伟达削减了对大型科技公司的H100供应,转而将这部分产能交给了CoreWeave等“自家兄弟”——它们曾确保不会自研芯片。
从结果来看,这一战略不仅避免了囤积现象的出现,也确实抢到了大型科技公司的蛋糕:
例如前文提到的Stability AI,在2022年底时一直将亚马逊AWS视作唯一云服务商;然而到了今年3月,困于算力不足的Stability AI,悄悄叩开了CoreWeave的大门。
事实上,英伟达手中并非仅有CoreWeave一张牌。这位手握H100的投资人,还投资了同为云计算公司的Lambda Labs,以及三家从事大模型、应用开发的明星初创企业。

前DeepMind联合创始人苏莱曼创办的Inflection AI,也接受了英伟达的投资
在亩产十万大模型的当下,H100是比美元还珍贵的硬通货,也为英伟达创造了一个宝贵的窗口期:尽可能让更多公司用上H100,趁早建立起生态,“把朋友搞得多多的”。
那么这个窗口期能持续多久呢?
尾声
英伟达的一系列“骚操作”已经引来了美国反垄断机构的注意,同时,全球疯抢H100的现状,很可能不会长期持续下去。
正如前文所述,H100产能受限是因为台积电和SK海力士的预备产能不足;随着新产线陆续落地,短缺状况会逐渐得到缓解。
除此之外,旺盛的需求也未必会延续下去。
事实上,越来越多的科技公司和研究机构都选择将大模型开源。随着市场上的优质开源模型越来越多,初创企业和研究机构可以不必再自己动手训练,转而直接下载开源模型,根据自身业务需求进行开发或者推理。
Meta发布开源大模型Llama后,斯坦福、卡内基梅隆等多所高校的研究人员就曾联合起来,以此为基础打造了开源大模型Vicuna,很快便突破了200万次下载。
Vicuna
在肉眼可见的未来,算力的主要使用场景很可能会从训练转向推理——届时,H100便不再是独孤求败了。因为不同于追求极致效率的训练场景,AI推理其实更看重性价比。
另一方面,以大模型为代表的生成式AI如今面临的问题在于:面对高昂的算力成本,除了英伟达,大家都还没赚到钱。
2006年CUDA平台推出时,英伟达以超脱于行业的前瞻性推动了AI的飞速进步。而如今,英伟达气势如虹的业绩似乎也是一种拷问:它是不是已经从AI的推动者,变成了AI前进的阻力?

参考资料
[1] Nvidia Muscles Into Cloud Services, Rankling AWS,The Information
[2] OpenAI CEO Sam Altman testifies at Senate artificial intelligence hearing | full video,CBS News
[3] Google Gemini Eats The World – Gemini Smashes GPT-4 By 5X, The GPU-Poors,Semi Analysis
[4] The Desperate Hunt for the A.I. Boom’s Most Indispensable Prize,The New York Times
[5] Nvidia H100 GPUs: Supply and Demand,GPU Utils
[6] Saudi Arabia and UAE race to buy Nvidia chips to power AI ambitions,Financial Times
[7] MPT-30B: Raising the bar for open-source foundation models
[8] China’s internet giants order $5bn of Nvidia chips to power AI ambitions,Financial Times
[9] AI Capacity Constraints - CoWoS and HBM Supply Chain,Semi Analysis
[10] Insight: Inside Meta's scramble to catch up on AI,Reuters
[11] Jim keller发声:世界憎恨垄断,GPU不是全部,半导体行业观察
[12] Nvidia Makes Nearly 1,000% Profit on H100 GPUs: Report,Toms Hardware
[13] 深度学习革命,凯德·梅茨
[14] 英伟达帝国的一道裂缝,饭统戴老板
[15] CoreWeave came ‘out of nowhere.’ Now it’s poised to make billions off AI with its GPU cloud,Venture Beat
[16] Why Nvidia Aids Cloud Rivals of AWS, Google and Microsoft,The Information
[17] TPUv5e: The New Benchmark in Cost-Efficient Inference and Training for <200B Parameter Models,Semi Analysis
[18] Nvidia’s Hot Streak May Not Last Forever,The Information
编辑:李墨天
视觉设计:疏睿
责任编辑:陈彬
研究支持:何律衡
